Lambda 함수로 .pdf 파일 업로드 후 첫번째 페이지 썸네일 이미지 생성하기
현재 진행하고 있는 프로젝트에서 구현한 이미지 업로드 기능을 개선한 과정을 정리해보았다.
문제
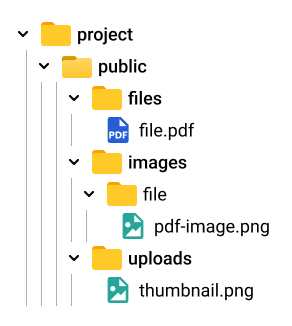
> 기존 Backend 디렉토리
프론트에서 .pdf파일을 업로드 할 경우, public 폴더에 안에 디렉토리를 생성했다.
files 폴더는 .pdf파일 원본, images/file 폴더는 .pdf파일 한장 한장을 이미지로 생성한 파일들과 uploads 폴더는 썸네일 이미지 한 폴더로 구분하여 저장하는 방식으로 구성되어 있다.
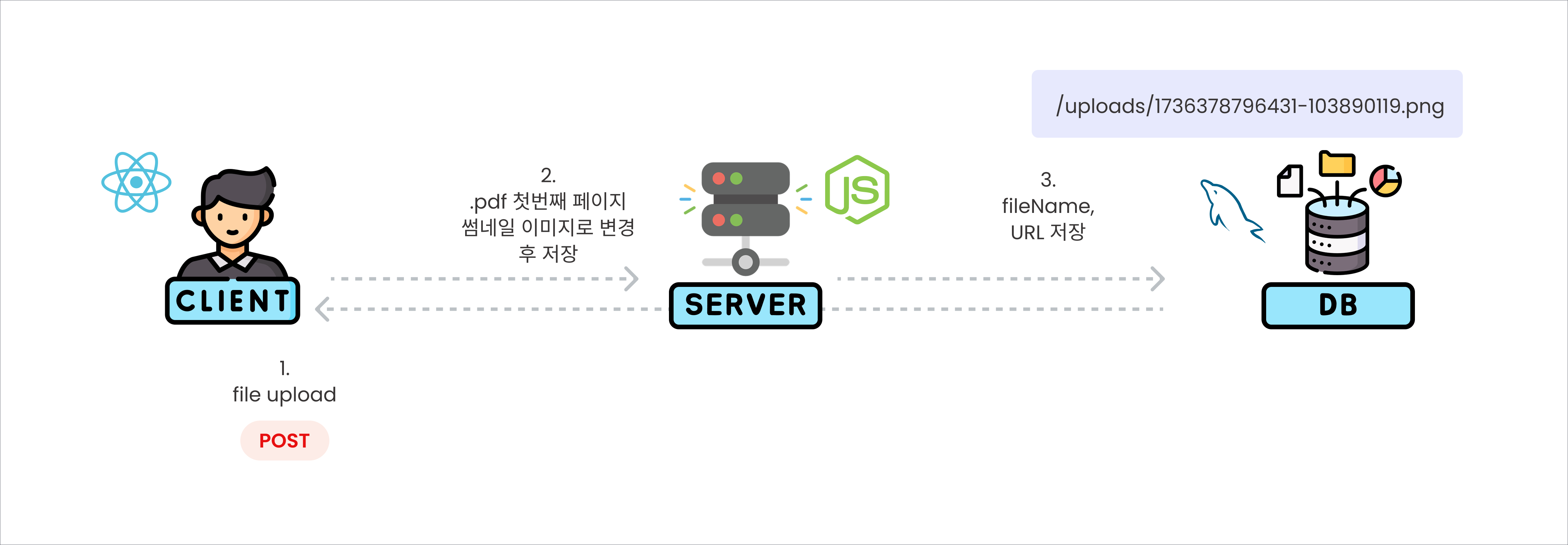
> Backend에서 모든 로직을 처리
이러한 로직 구성은 디스크 공간 낭비와 파일 조회 속도 저하를 초래하기 때문에 개선방법을 찾아보았다.
개선 방법
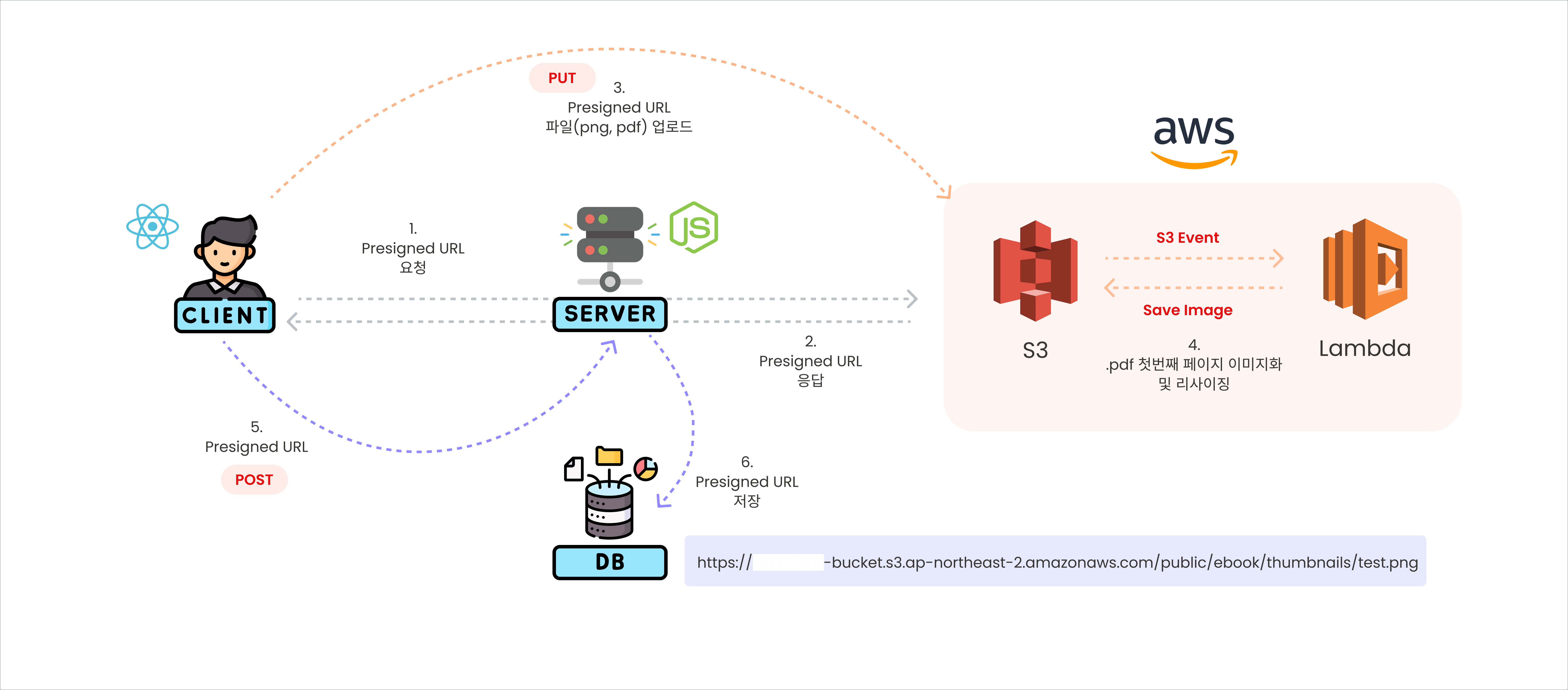
> 개선된 flow
- 클라이언트(React)가 서버(Nest.js)에 Presigned URL을 요청.
- 서버가 S3에 대한 임시 접근 권한이 있는 Presigned URL을 생성하여 클라이언트에게 반환.
- 클라이언트는 받은 Presigned URL을 사용하여 파일(PNG, PDF)을 직접 S3 버킷으로 업로드(PUT 요청).
- 파일이 S3에 저장되면 S3 이벤트가 트리거되어어 Lambda 함수를 실행시켜 PDF 첫번째 페이지를 이미지화하고 리사이징.
- 처리가 완료되면 클라이언트는 서버에 POST 요청을 보내 업로드가 완료되었음을 알림.
- 서버는 Presigned URL과 관련 메타데이터를 데이터베이스에 저장.
이 아키텍처를 사용해서 개선하므로써,
서버를 거치지 않고 클라이언트가 직접 S3에 파일을 업로드하므로 서버 부하가 감소하고
Lambda를 통한 서버리스 이미지 처리로 확장성이 높다.
Presigned URL을 사용할때 만료 시간을 부여 하여 보안을 유지하면서도 효율적인 업로드가 가능며 S3와 Lambda의 이벤트 기반 아키텍처로 비동기 처리까지 가능하게 했다.
Lambda 함수에서 임시 파일 경로를 사용하는 이유
Lambda는 서버리스 환경으로, 영구적인 파일 시스템에 접근할 수 없는 대신 /tmp 디렉토리만 쓰기 가능한 임시 저장소로 제공된다.
Lambda 함수는 pdftoppm 명령줄 도구를 사용하여 PDF를 이미지로 변환한다. 이러한 외부 프로세스는 실제 파일 경로를 인자로 받아야 하므로, S3에서 가져온 PDF 데이터를 임시 파일로 저장해야 한다.
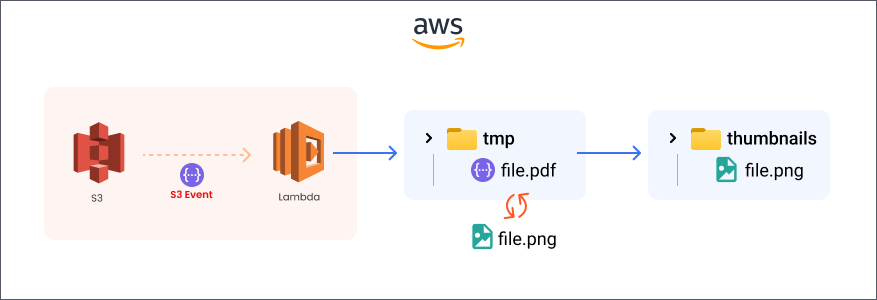
> Lambda 함수 동작 방식
적용 방법 - AWS Setting
1. IAM 사용자 생성 후 액세스 키를 발급받는다.
• 권한 : AmazonS3FullAccess
2. 역할(Role) 생성.
• 신뢰할 수 있는 엔터티 유형 : AWS 서비스
• 사용 사례 > 서비스 또는 사용 사례 : Lambda
• 권한 추가 > 권한 정책 :
- AmazonS3FullAccess
- AWSLambdaBasicExecutionRole
• 역할 이름 : generateThumbnail
3. S3 버킷 생성
• 버킷 이름 : bucket
• Amazon 리소스 이름(ARN) : arn:aws:s3:::bucket
• AWS 리전 : 아시아 태평양(서울) ap-northeast-2
• 모든 퍼블릭 액세스 차단 - 비활성
• CORS(Cross-origin 리소스 공유)
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE",
"HEAD"
],
"AllowedOrigins": [
"http://localhost:3000"
],
"ExposeHeaders": [
"ETag"
]
}
]
> 버킷 생성 시, 체크 확인
4. Lambda 함수 생성
• 함수 이름 : pdf-thumbnail-lamda
• 런타임 : Node.js 22.x
• 아키텍처 : x86_64
• 기본 실행 역할 변경 > 기존 역할 사용 : generateThumbnail
5. 트리거 추가
• 트리거 구성 : S3
• 버킷 : s3/bucket
• 이벤트 유형 : 모든 객체 생성 이벤트
• 접두사 : public/ebook
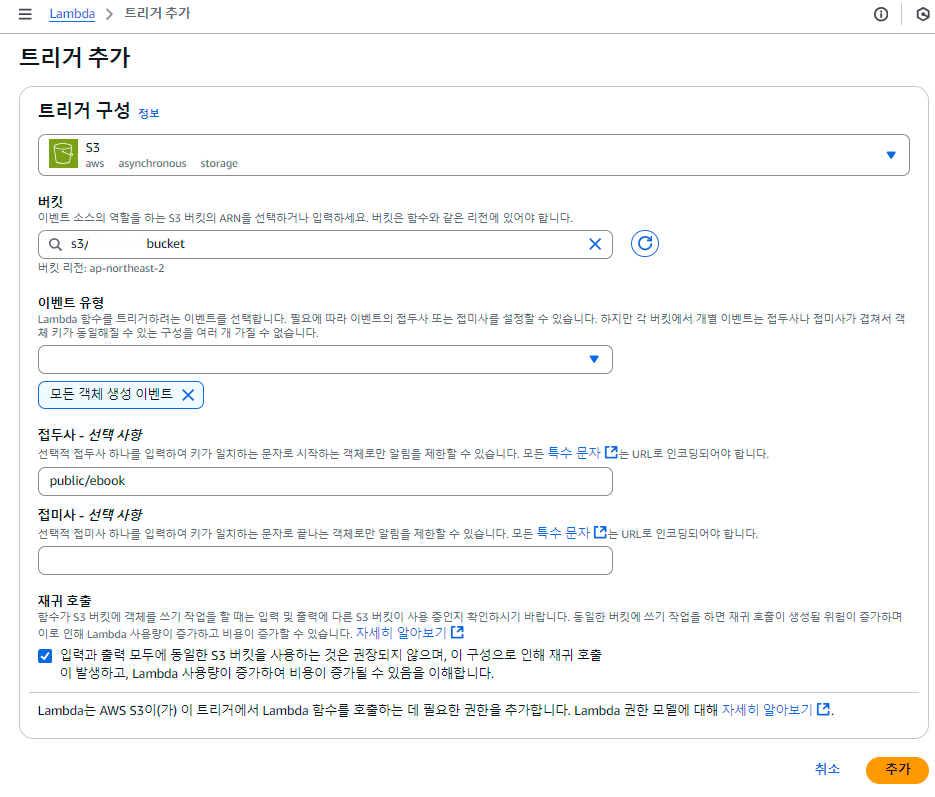
> 트리거 추가
> 구성 셋팅
6. S3 이벤트 알림 설정
> S3 이벤트 알림 설정
적용 방법 - Lambda Code
1. VS Code
> 디렉토리
-
필요 패키지 설치
$ npm install --platform=linux --arch=x64 sharp aws-sdk fs child_process pdf-poppler pdf-lib puppeteer-core chrome-aws-lambda pdf.js-extract -
index.mjs
import pkg from 'aws-sdk'; import sharp from 'sharp'; import { spawnSync } from 'child_process'; import \* as fs from 'fs/promises'; import path from 'path'; // AWS SDK에서 S3 서비스 객체 생성 const { S3 } = pkg; const s3 = new S3(); /\*\* - 썸네일 키 생성 함수 - @param {string} sourceKey - 원본 파일 경로 - @returns {string} 썸네일 파일 경로 \*/ const createThumbnailKey = (sourceKey) => { const fileName = path.basename(sourceKey, '.pdf'); return `${path.dirname(sourceKey)}/thumbnails/${fileName}.png`; }; /\*\* - 안전한 메타데이터 키 생성 함수 - @param {string} sourceKey - 원본 파일 경로 - @returns {string} Base64로 인코딩된 안전한 키 \*/ const createSafeMetadataKey = (sourceKey) => { return Buffer.from(sourceKey).toString('base64'); }; /\*\* - S3에 썸네일 업로드 함수 - @param {Object} params - 업로드 파라미터 - @returns {Promise} S3 putObject 작업의 Promise \*/ const uploadThumbnailToS3 = async (params) => { const { sourceBucket, thumbnailKey, imageBuffer, sourceKey, isFallback = false } = params; const metadata = { 'original-key-encoded': createSafeMetadataKey(sourceKey) }; if (isFallback) { metadata['is-fallback-icon'] = 'true'; } return s3.putObject({ Bucket: sourceBucket, Key: thumbnailKey, Body: imageBuffer, ContentType: 'image/png', ACL: 'public-read', Metadata: metadata }).promise(); }; /\*\* - 성공 응답 생성 함수 - @param {Object} params - 응답 파라미터 - @returns {Object} 응답 객체 \*/ const createSuccessResponse = (params) => { const { thumbnailKey, isFallback = false } = params; return { statusCode: 200, body: JSON.stringify({ message: isFallback ? '기본 썸네일 생성 완료' : 'PDF 썸네일 생성 완료', thumbnail: thumbnailKey, ...(isFallback && { fallback: true }) }) }; }; /\*\* - 기본 썸네일 이미지 생성 함수 - @returns {Promise<Buffer>} 생성된 이미지 버퍼 \*/ const createDefaultThumbnail = async () => { return sharp({ create: { width: 300, height: 300, channels: 4, background: { r: 245, g: 245, b: 245, alpha: 1 } } }) .composite([ { input: Buffer.from(` <svg width="300" height="300" xmlns="http://www.w3.org/2000/svg"> <rect width="100%" height="100%" fill="#f5f5f5"/> <text x="50%" y="50%" font-family="Arial" font-size="42" font-weight="bold" fill="#cc0000" text-anchor="middle" dominant-baseline="middle">PDF</text> <text x="50%" y="65%" font-family="Arial" font-size="16" fill="#444444" text-anchor="middle" dominant-baseline="middle">문서 썸네일</text> </svg>`), top: 0, left: 0, } ]) .png() .toBuffer(); }; // Lambda 핸들러 함수 정의 (비동기 함수) export const handler = async (event) => { // 임시 파일 경로 설정 const tempPdfPath = '/tmp/temp.pdf'; const tempImgPath = '/tmp/output'; try { // S3 이벤트에서 트리거된 버킷 이름 추출 const sourceBucket = event.Records[0].s3.bucket.name; // S3 이벤트에서 트리거된 객체 키(파일 경로) 추출 및 URL 디코딩 const sourceKey = decodeURIComponent(event.Records[0].s3.object.key); console.log('처리 중인 버킷:', sourceBucket); console.log('처리 중인 키:', sourceKey); // 'public/ebook' 경로에 있는 파일만 처리하도록 필터링 if (!sourceKey.includes('public/ebook')) { console.log('public/ebook 폴더의 파일이 아닙니다:', sourceKey); return; } // 파일이 PDF 확장자를 가진 경우만 처리 if (!sourceKey.toLowerCase().endsWith('.pdf')) { console.log('PDF 파일이 아닙니다:', sourceKey); return; } // 썸네일 키 생성 const thumbnailKey = createThumbnailKey(sourceKey); // S3에서 원본 PDF 파일 가져오기 const originalPdf = await s3.getObject({ Bucket: sourceBucket, Key: sourceKey }).promise(); // S3에서 가져온 PDF 내용을 임시 파일로 저장 await fs.writeFile(tempPdfPath, originalPdf.Body); try { console.log('PDF 첫 페이지 변환 시도 중...'); // pdftoppm 명령어를 사용해 PDF의 첫 페이지만 PNG로 변환 const result = spawnSync('pdftoppm', [ '-png', // PNG 형식으로 출력 '-singlefile', // 단일 파일로 출력 '-f', '1', // 첫 페이지부터 '-l', '1', // 첫 페이지까지만 처리 tempPdfPath, // 입력 PDF 파일 경로 tempImgPath // 출력 이미지 파일 경로 (확장자 없이) ]); // 프로세스 실행 중 오류 발생 시 예외 발생 if (result.error) { throw result.error; } // 프로세스가 성공적으로 종료되지 않은 경우 예외 발생 if (result.status !== 0) { throw new Error(`pdftoppm failed with exit code ${result.status}: ${result.stderr.toString()}`); } console.log('PDF 변환 성공'); // 생성된 PNG 파일 경로 (확장자 추가) const pngFile = `${tempImgPath}.png`; // 변환된 이미지 파일이 실제로 존재하는지 확인 await fs.access(pngFile); // 변환된 이미지 파일 읽기 const imageBuffer = await fs.readFile(pngFile); // sharp를 사용해 이미지 크기 조정 (300x300 썸네일 생성) const thumbnail = await sharp(imageBuffer) .resize(300, 300, { fit: 'contain', // 비율 유지하면서 맞추기 background: { r: 255, g: 255, b: 255, alpha: 1 } // 흰색 배경 }) .toBuffer(); // 생성된 썸네일을 S3에 업로드 await uploadThumbnailToS3({ sourceBucket, thumbnailKey, imageBuffer: thumbnail, sourceKey }); // 사용이 끝난 임시 PDF 파일 삭제 await fs.unlink(tempPdfPath); // 사용이 끝난 임시 PNG 파일 삭제 await fs.unlink(pngFile); console.log(`썸네일 생성 완료: ${thumbnailKey}`); // 성공 응답 반환 return createSuccessResponse({ thumbnailKey }); } catch (conversionError) { console.error('PDF 변환 오류:', conversionError); console.log('기본 썸네일 이미지를 생성합니다.'); try { // 기본 썸네일 이미지 생성 const defaultThumbnail = await createDefaultThumbnail(); // 생성된 기본 썸네일을 S3에 업로드 await uploadThumbnailToS3({ sourceBucket, thumbnailKey, imageBuffer: defaultThumbnail, sourceKey, isFallback: true }); console.log(`기본 썸네일 생성 완료: ${thumbnailKey}`); // 임시 PDF 파일 존재 시 삭제 (fs.existsSync 대신 fs.access 사용) try { await fs.access(tempPdfPath); await fs.unlink(tempPdfPath); } catch (err) { // 파일이 없는 경우 무시 } // 성공 응답 반환 (대체 이미지 사용) return createSuccessResponse({ thumbnailKey, isFallback: true }); } catch (fallbackError) { console.error('기본 썸네일 생성 오류:', fallbackError); throw new Error('PDF 변환 및 기본 썸네일 생성 모두 실패했습니다.'); } } } catch (error) { console.error('Error: ', error); // 오류 응답 반환 return { statusCode: 500, body: JSON.stringify({ message: 'PDF 썸네일 생성 실패', error: error.message }) }; } };
2. Lambda 코드 소스 업로드
- Lambda 폴더
.zip으로 압축 - S3 > 버킷 > bucket > 업로드
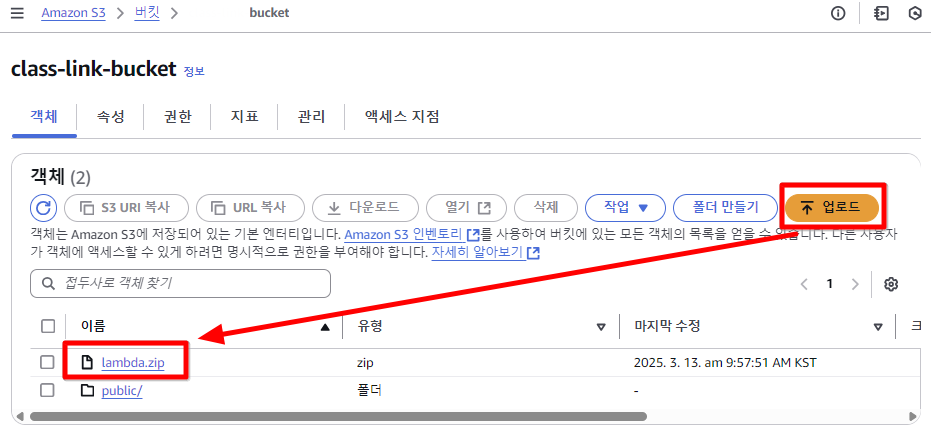
> Lambda 코드 압축 파일 S3에 업로드 -
Lambda > 함수 > pdf-thumbnail-lamda > Amazon S3 위치 > 객체 URL 붙여넣기.
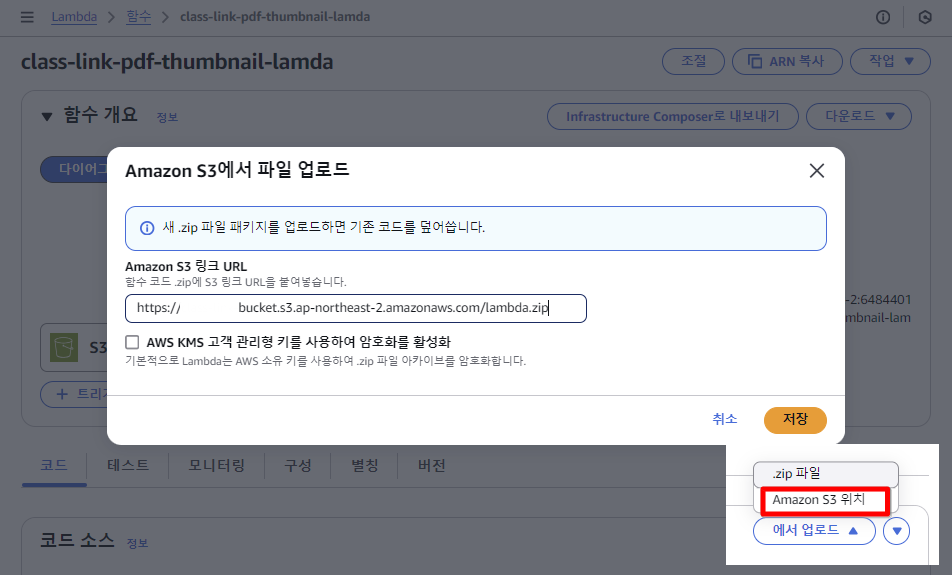
> Lambda 함수 코드 업로드
3. 외부 라이브러리 Layers 추가
poppler-lambda-layer디렉토리 생성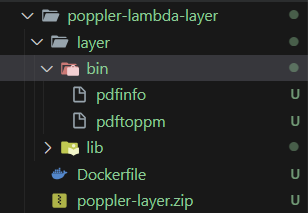
> 계층 디렉토리-
Dockerfile 생성
# Dockerfile FROM amazonlinux:2 # 필요한 패키지 설치 RUN yum update -y && \ yum install -y poppler-utils zip && \ yum clean all # Lambda 레이어 디렉토리 구조 생성 # /opt는 Lambda 레이어의 기본 경로 RUN mkdir -p /opt/bin # 필요한 바이너리 파일 복사 RUN cp /usr/bin/pdftoppm /opt/bin/ && \ cp /usr/bin/pdfinfo /opt/bin/ && \ chmod 755 /opt/bin/\* # 필요한 공유 라이브러리 복사 RUN mkdir -p /opt/lib && \ ldd /usr/bin/pdftoppm | grep "=> /" | awk '{print $3}' | \ xargs -I '{}' cp -v '{}' /opt/lib/ WORKDIR /opt CMD ["/bin/bash"] -
Docker 이미지 빌드
$ docker build -t poppler-lambda-layer . -
컨테이너 실행 및 레이어 파일 추출
# 컨테이너 실행 docker run --name poppler-container poppler-lambda-layer # 로컬에 레이어 구조 생성 mkdir -p layer # 컨테이너에서 /opt 디렉토리 내용 복사 docker cp poppler-container:/opt/. layer/ # 사용한 컨테이너 삭제 docker rm poppler-container - ZIP 파일 생성
4. Lambda 계층 생성 및 추가
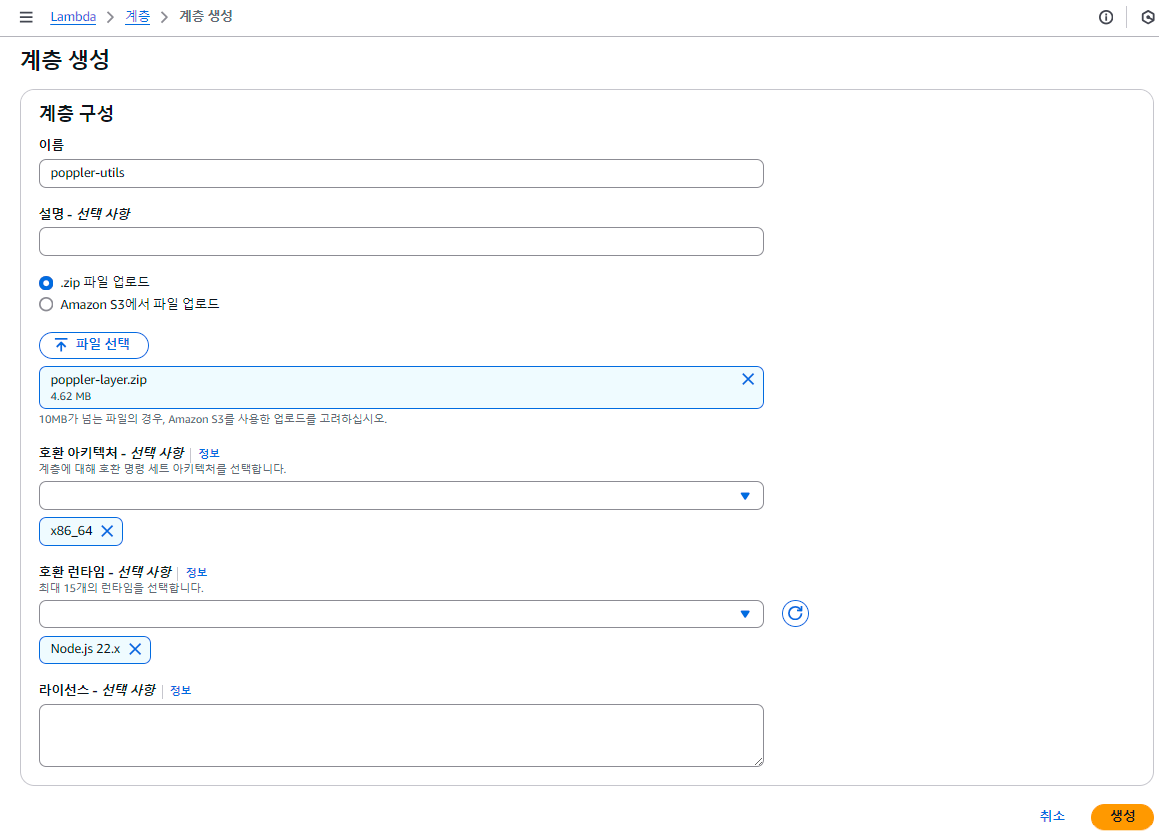
> 계층 생성
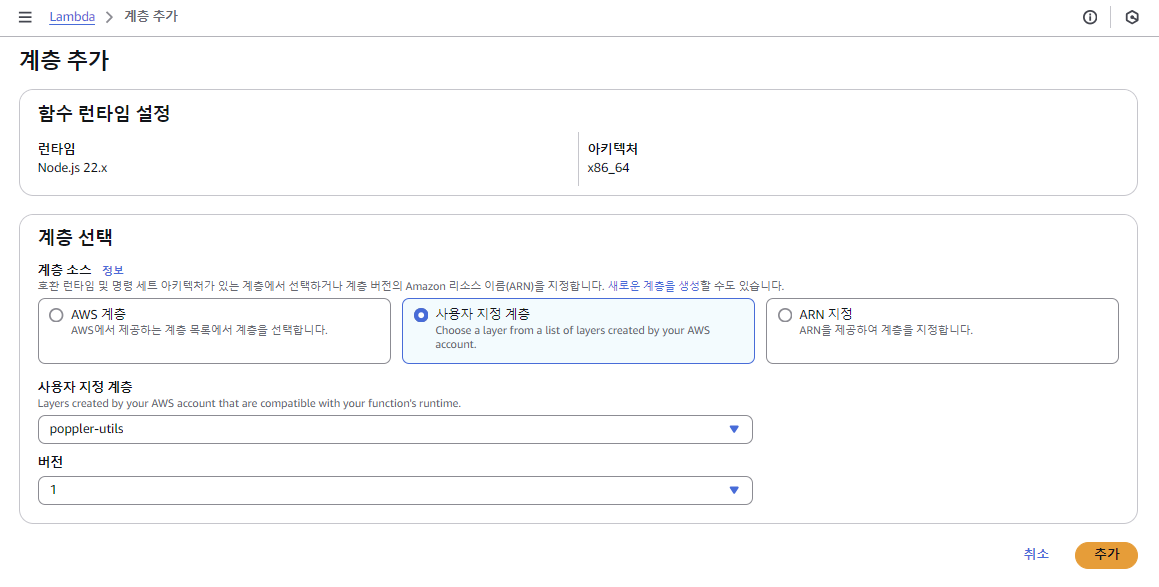
> 계층 추가
5. 테스트
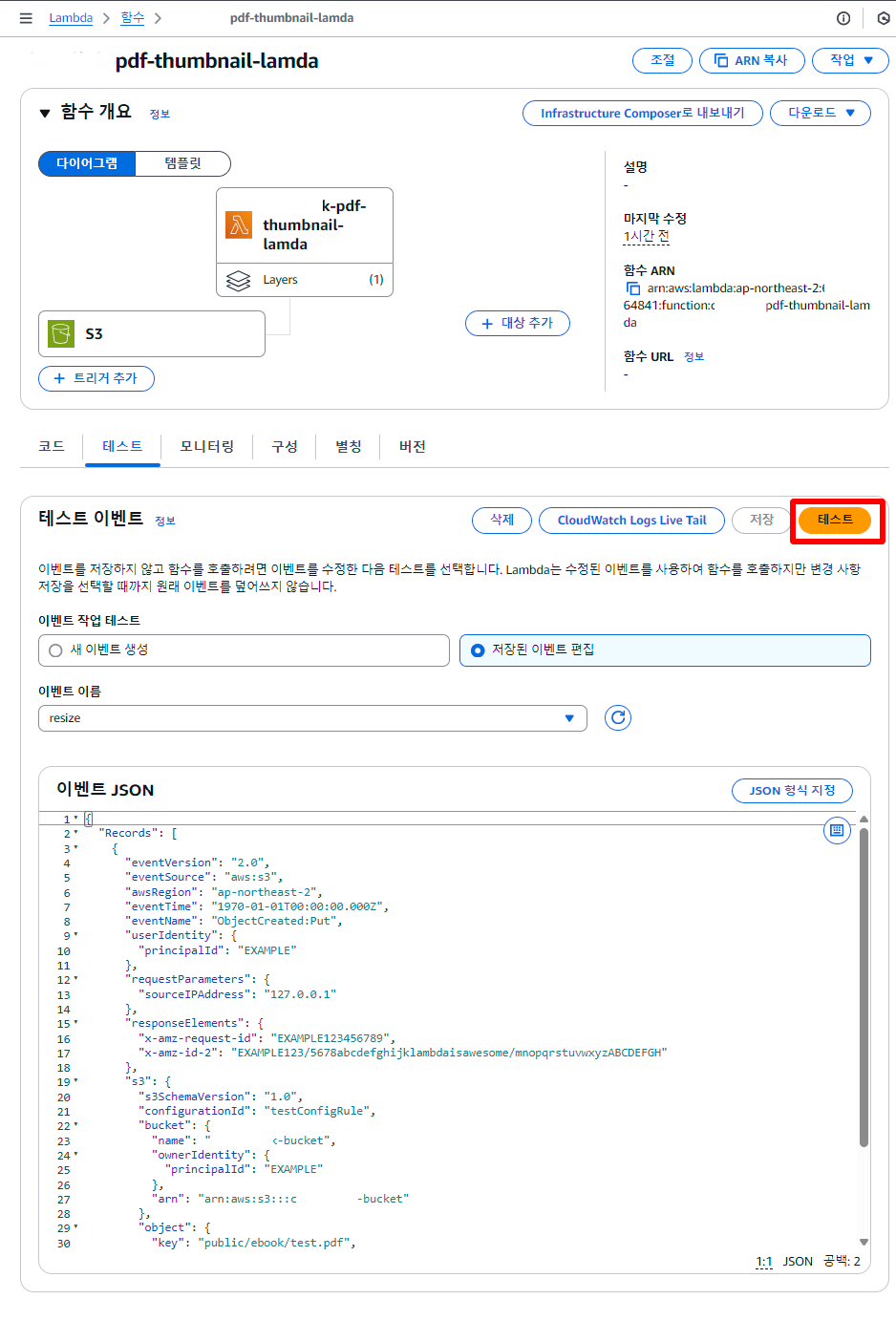
> 이벤트 JSON
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "ap-northeast-2", // 버킷이 생성된 리전
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "EXAMPLE123456789",
"x-amz-id-2": "EXAMPLE123/5678abcdefghijklambdaisawesome/mnopqrstuvwxyzABCDEFGH"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "bucket", // 버킷 명
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::bucket" // 버킷 ARN
},
"object": {
"key": "public/ebook/test.pdf", // 실제 경로에 업로드된 파일
"size": 1024,
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901"
}
}
}
]
}
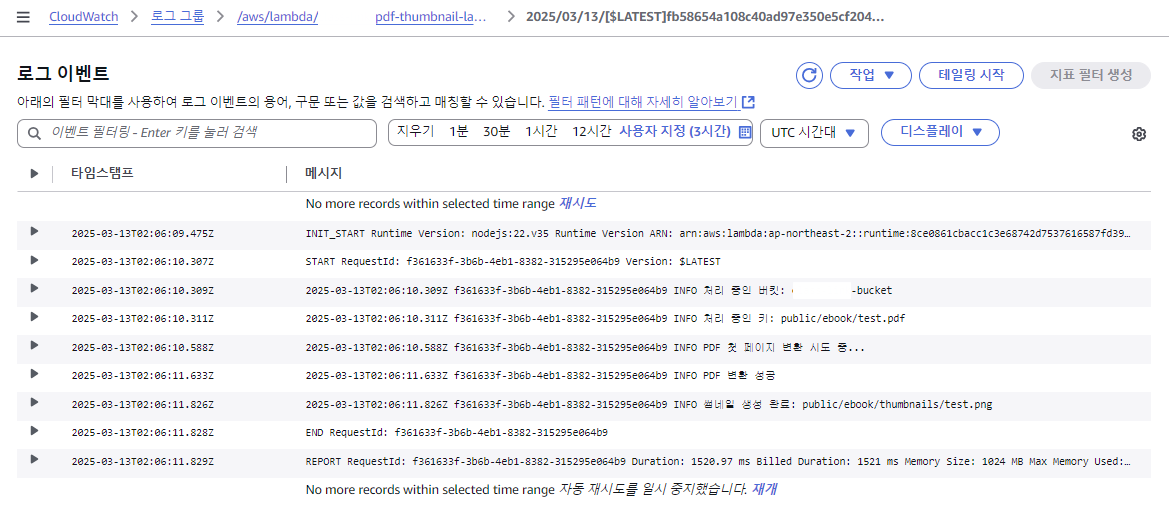
> 테스트 로그 확인
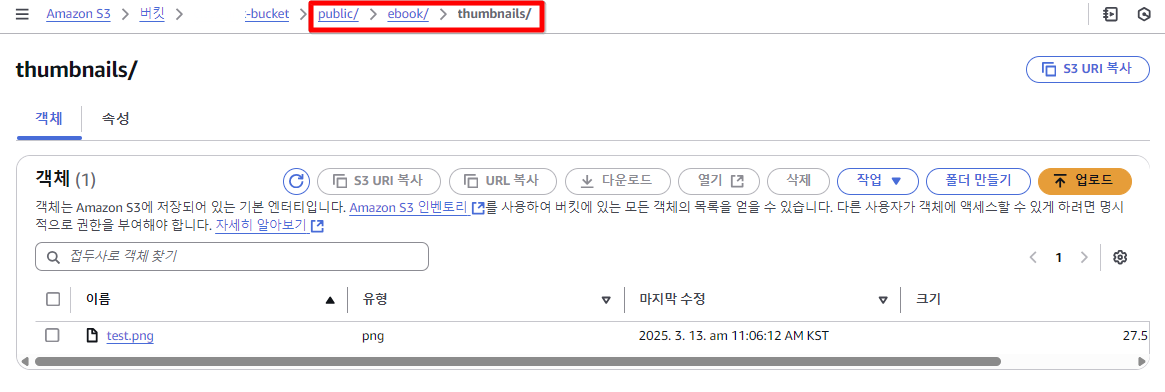
> 썸네일 이미지 생성 확인
마무리
프론트 개발자에서 풀스택으로 일하게 되면서 백엔드에서는 파일 업로드 기능을 어떻게 처리하는지에 대해 알게 되었고, AWS를 사용해 보면서 S3와 Lambda의 개념에 대해서도 공부할 수 있었다.
앞으로도 좀 더 개선할 수 있는 방법에 대해 공부하면서 개선해 나가야겠다.
참고
Lambda를 활용한 S3 이미지 리사이징
[AWS S3+Lambda] 이미지 처리 2탄: Image Resizing으로 썸네일 이미지 만들기
[AWS] 📚 람다 - 이미지 리사이징 서비스 (S3 / API Gateway) 구현하기